C++ Assembler Win32 STL Benchmarking Algorithms
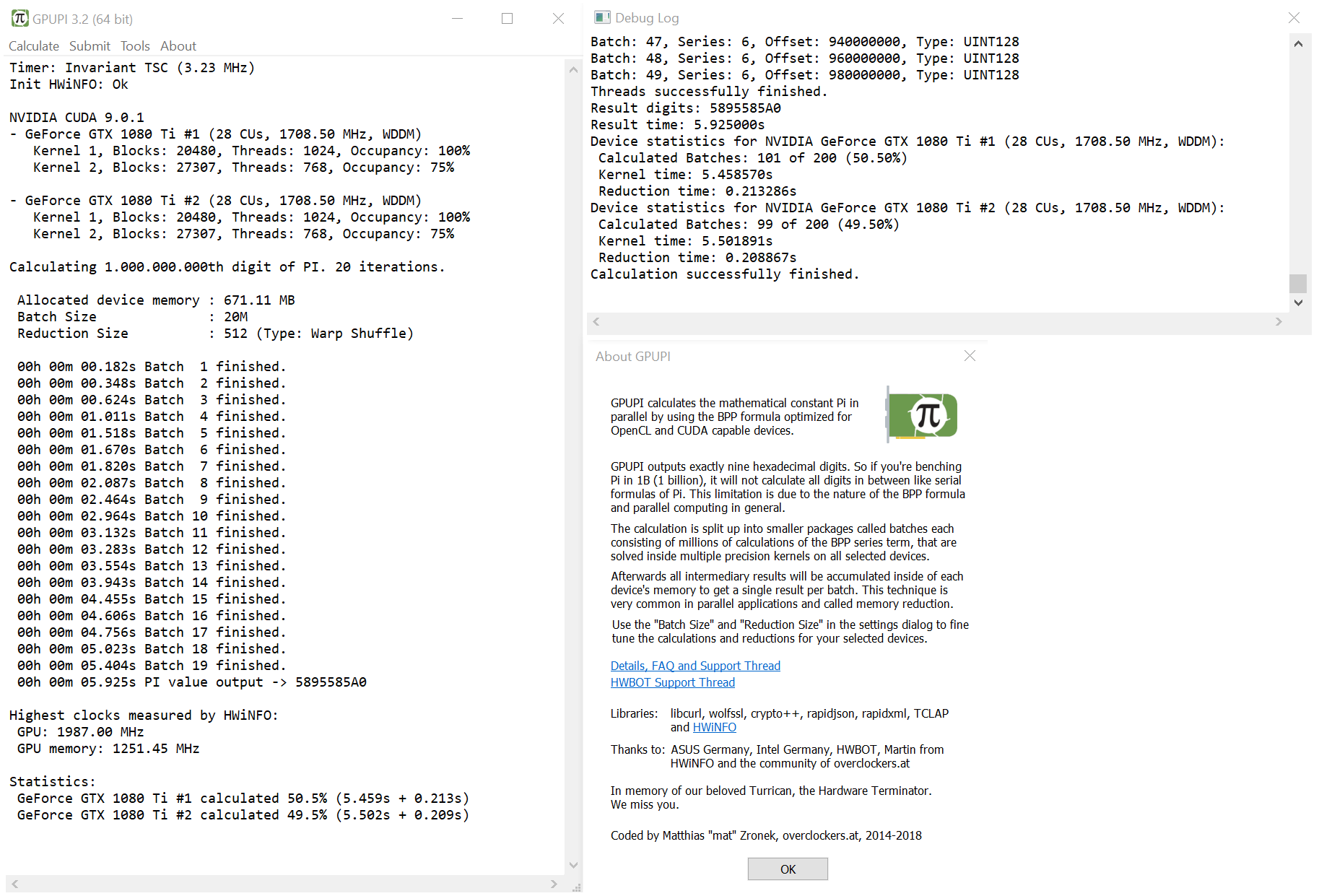
GPUPI calculates the mathematical constant Pi in parallel by using the BPP formula and optimizing it for OpenCL and CUDA capable devices like graphics cards and main processors. It's implemented with C++, STL and pure Win32 to avoid unnecessary dependencies. The result of the benchmark are exactly nine digits of Pi in hexadecimal.
The calculation is split up into smaller packages called batches which themselves consist of millions of calculations of the BPP series term on each possible compute core of all selected devices. Afterwards millions of intermediary results will be accumulated inside the device's memory to get a single result per batch. This technique is very common in parallel applications and called memory reduction. GPUPI optimizes the reduction process thoroughly for you device's capabilities.
The benchmark relies heavily on 64 bit integer performance. Additionally each series term calculation of the BPP formula needs a division using double precision. The result is stored and finally accumulated as doubledouble, two doubles combined for a necessary high precision. Starting with one billion digits each kernel has to make use of custom 128 bit integer algorithms as well.
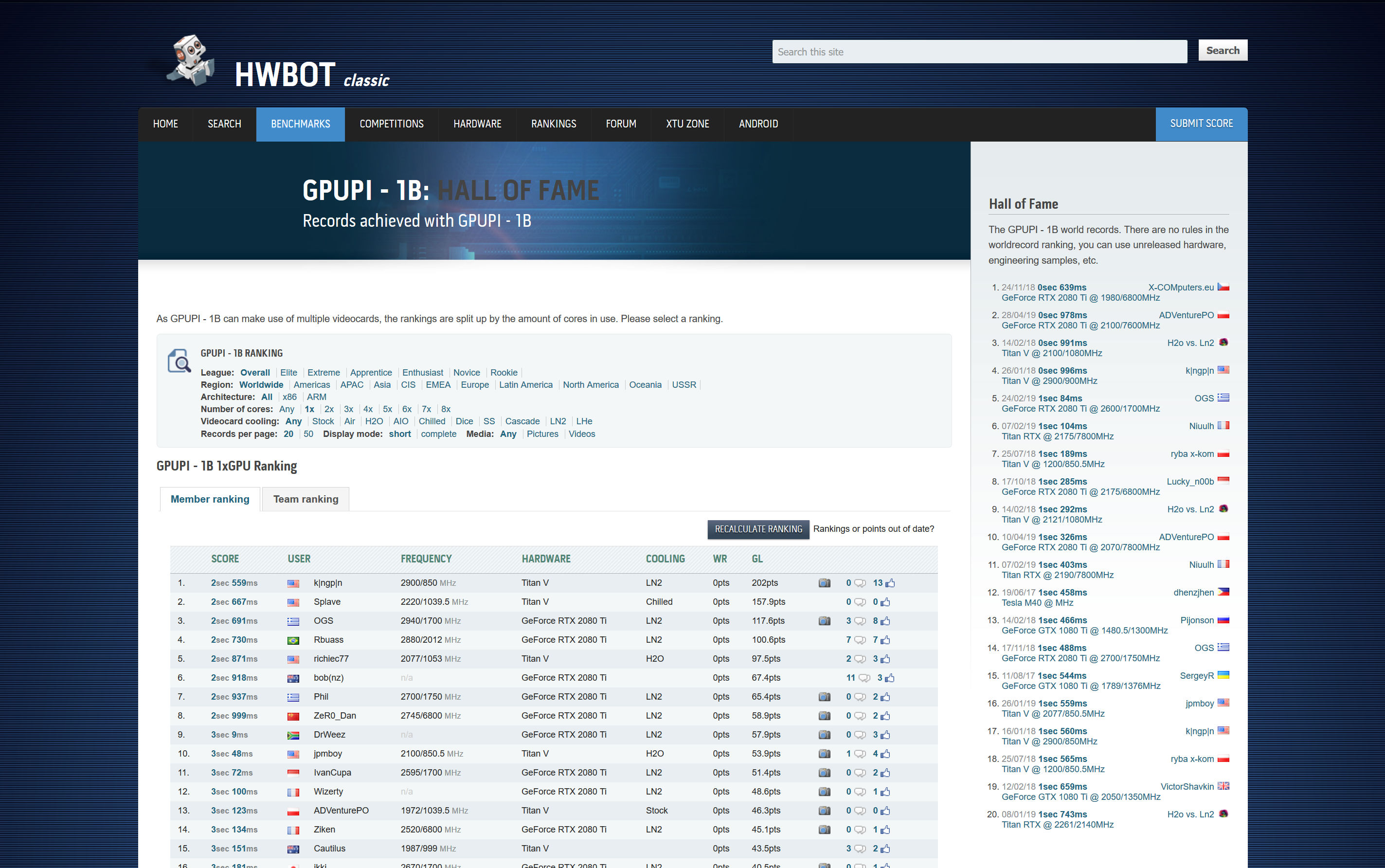
GPUPI has been downloaded more than 300,000 times.
{kind=link}
{kind=link}
{kind=link}